Databricks LTAP and the Unfinished Problem of Unified Data

Boaz Palgi
CEO and Co-Founder
Dive into RegattaDB's architecture in our upcoming webinar — Register here.
Boaz Palgi
CEO and Co-Founder
Databricks made a significant announcement at Data + AI Summit this week. LTAP, or Lake Transactional/Analytical Processing, is their answer to a problem the industry has been trying to solve for decades: how do you run transactional and analytical workloads on the same data without paying for pipelines, replication, and the latency that comes with both?
While the announcement is worth taking seriously, it is also worth reading it carefully.
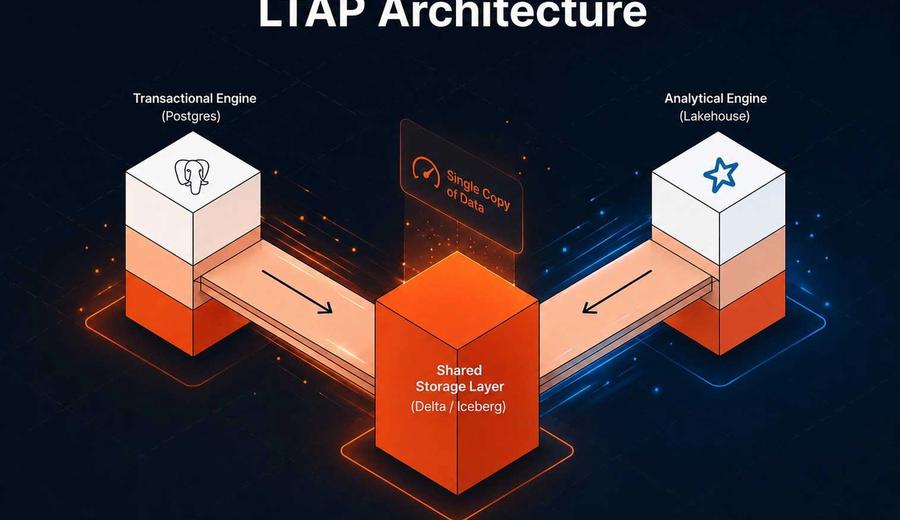
Lakebase, Databricks' serverless Postgres service built on object storage, is generally available. LTAP is the architectural concept layered on top. Rather than writing transactional data in Postgres format and running a CDC pipeline to convert it into columnar format for the Lakehouse, Lakebase now writes transactional data directly into Delta and Iceberg formats at the point of write via copy-on-write. The lake and the transactional layer share the same physical data from the moment it lands.
It is a meaningful contribution, but is also, not yet available: LTAP itself is listed as coming soon and Lakehouse//RT, the Reyden compute engine that delivers sub-100ms analytical query latency on Delta and Iceberg tables, is in beta.
The HTAP premise is a single system that could handle transactions, analytics, and semantic workloads without moving data between them. The problem is complex. OLTP workloads require low-latency random I/O for point reads and writes. OLAP workloads require high-throughput sequential scans across large data sets. Vector workloads require approximate nearest-neighbor search across high-dimensional embeddings. Putting any two of these on the same compute engine creates resource contention. Putting all three on the same engine exasperates this challenge.
Further, OLTP requires data-layouts that will provide optimal good performance for transactions, and a variety of alternative data-layouts chosen by HTAP databases for analytics don’t work well for OLTP. The “transformation” of the data is a challenge, especially when you want the OLAP data to be completely current.
Zero-ETL approaches and CDC pipelines were attempts to hide that contention by keeping separate systems but reducing the friction between them. Snowflake recently announced version of this solution. They don’t solve the underlying problem, they simply move it.
LTAP takes a slightly different approach to HTAP but still doesn't address the combined engine challenge. Rather than forcing both workloads into a single execution engine, it keeps them separate: Postgres handles transactions, Spark and the Lakehouse handle analytics. What changes is the storage layer. The OLTP layer will “copy on write” and use buffers between it and the OLAP storage to eventually push data to the warehouse.
The answer to this question lies in the detail of this implementation and the Databricks announcement does not fully answer.
From what we can gather (there is limited technical detail), in LTAP, Postgres writes to its WAL and buffer cache first, the caching layer then converts rows to columnar format, and then data lands in object storage in Delta or Iceberg format. The conversion step presents a concurrency question.
There are two consistency domains in this architecture, not one. Postgres maintains ACID semantics on the transactional side. Delta Lake maintains snapshot isolation on the analytical side. Between them sits a caching and conversion layer that introduces a variable and unpublished flush window.
A transaction that commits in Postgres is immediately visible to other Postgres queries. It is not visible to the Lakehouse analytical engine until it has been converted and flushed to object storage. Databricks describes data as "immediately queryable" but does not define what immediately means under load.
A long-running Spark query reads from a snapshot as of the moment it starts. There are two potential problems here. First, transactions that commit in Postgres after that point are not visible to that query. Second, and more importantly, what happens if a transaction commits before the analytical query started and it is waiting to be flushed? This is a real concern. Further, even if the flush has started, there may be delay due to the transformation processing to the column store format. So ultimately, it is quite possible that the analytical query is not just out of date, but incorrect.
Databricks has not published a bound on these potential issues yet. We merely call them out as challenges.
This is a fairly important concern to investigate, especially as we look to use a unified database for agentic operations. An agent that needs to read live transactional state, run an analytical join across historical records, and execute a transaction based on the result is still crossing an engine boundary. LTAP removes the data synchronization cost of that crossing, but it does not remove the crossing.
The benchmark numbers Databricks published for Lakehouse//RT are measured against TPC-H Q6: a single-table scan with filters and a simple aggregation. Q6 is a legitimate benchmark for scan speed, predicate pushdown, and vectorized execution. It does not test joins. The performance profile of complex multi-table analytical queries running concurrently with high-frequency transactional writes is not addressed by the published numbers.
When Databricks says transactional and analytical workloads "scale independently," that is accurate and useful for many workloads. For agents that need both simultaneously within a single operation, independent scale means the coordination between engines still has to happen somewhere. In LTAP, that somewhere is application logic.
Agent systems need three capabilities running simultaneously: transact on live operational data, reason analytically over historical patterns, and retrieve semantically similar context through vector search. LTAP attempts to ddresses the first two at the storage layer. Vector search remains an extension bolted to the Postgres transactional engine, with the contention and single-node ceiling problems being significant at any scale.
These three workloads have fundamentally different compute profiles. A system that handles all three without degradation requires that the concurrency model be designed around all three from the start. LTAP gets the data into one place.
The hardest problem with unification of OLTP and OLAP is the aligning on a single concurrency model.
Most attempts at unification start with an existing system and extend it. Add a columnar store to a transactional database. Bolt a vector index onto Postgres. Connect an analytical engine to an operational one via shared storage. Each of these approaches inherits the architectural assumptions of the systems it started with. Those assumptions were made for different workloads, under different constraints, at a different time. Modifying them at the edges does not change what they are at the core.
Running OLTP, OLAP, and vector workloads simultaneously without degradation requires rethinking how the database manages concurrent access, stores and retrieves data, handles version cleanup, and executes queries, from the storage layer through the query parser. RegattaDB was built from that constraint. A few specifics on what that means in practice:
The result is one schema, one connection, and one concurrency model across transactional, analytical, and vector workloads. Not three systems sharing a storage layer. One system, designed from the ground up to run all three.
The LTAP announcement reflects something the market has been moving toward for some time: the fragmented data stack is the bottleneck for AI agents. That is the right diagnosis, and we have been speaking of this for months. LTAP stops short as It does not produce a unified execution model, and for agent systems operating at scale, that distinction matters.
RegattaDB was built to answer the full problem. Not by extending an existing engine or connecting two systems at the storage layer, but by rethinking the database from the ground up for exactly this workload profile: high-concurrency agent systems that need to transact, analyze, and reason semantically over the same live data, simultaneously, without routing across engines or accepting degraded consistency guarantees.
That work is done. RegattaDB is in production, handling transactional, analytical, and vector workloads under a single concurrency model at scale. The architecture that LTAP points toward, one system, one concurrency model, no engine boundaries, is what RegattaDB delivers today.
For architects evaluating data infrastructure for agent systems, the questions worth asking are specific: Does the system maintain serializable consistency across millions of simultaneous agent reads and writes? Does it scale linearly with agent concurrency without sharding? Does it handle transactional, analytical, and semantic workloads under a single concurrency model without routing across engines? Those questions have concrete answers.
RegattaDB answers all of them. LTAP answers some of them.

RegattaDB Launches as the Database Built for AI Agents — Unifying OLTP, OLAP, and Vectors RegattaDB unifies transactions, analytics,...
A few weeks ago we published an analysis of Databricks LTAP and the architectural questions it left open. One question in particular...
Things are moving fast. The market has shifted from "should we build agents" to "we are building and will...