We Rebuilt Our Website, Because We Rethought the Database

Jim Walker
Chief Product Officer
Dive into RegattaDB's architecture in our upcoming webinar — Register here.
Jim Walker
Chief Product Officer
Things are moving fast. The market has shifted from "should we build agents" to "we are building and will need to deploy them at scale." And as these projects get to production, many realize that they are bottlenecked by the data layer beneath them.
Addressing the limitations of the legacy data stack will separate teams that build and release something durable from those that spend the next two years refactoring.
And the market knows this. It seems each week, we hear another database vendor or cloud provider propound that agents will need combined transactions and analytics at scale. While we agree with them, we take a slightly different tact at Regatta.
Agents do need fresh data, consistent context, and a single view of the business. This framing is accurate, but how we resolve this is limited by their architectures of the underlying databases. Automated pipelines are still pipelines. New storage formats don’t solve concurrency mismatches. None of these approaches will make the data layer “agent ready”.
Months ago, in The Shift to Agentic AI and a Modern Database, we described the triangle problem that prevents legacy databases from being both transactional and analytical at the same time. This constraint shapes the data layer most enterprises run today: a transactional database handling live business state, an analytical system handling reporting, and pipelines moving data between them. Humans tolerate the latency that is introduced because humans are slow. Agents do not.
There are three ways to approach the data layer for agent systems.
- Context Layer on Existing Systems:
Orchestrates queries across your current stack and an LLM interprets results. If the underlying systems are fragmented or stale, the intelligence layer inherits that directly.
- Extend Existing Architectures:
Where most are today. Reduce friction at the edges with transactional extensions to a warehouse, distributed SQL, and vector add-ons. The fragmentation at the center remains.
- Rebuild the Data Layer:
A single system handling transactions, analytics, and vector search natively with a shared concurrency model, no replication pipelines, and serializable consistency across all three. This is what RegattaDB is built on.
RegattaDB is a rethink of the database from the storage layer up through to the concurrency model and parser to be applicable to both transactional and analytical workloads. And we extended the architecture to accommodate vector processing because modern workloads, like agents, need to avoid insight lag, duplicated data and inconsistencies.
When we set off on our mission, the world had only dreamed of autonomous agents. It was sci-fi mostly. Today, we are in a new world where it seems that if you aren’t AI and agent based you are irrelevant. And while many scramble to add the “for AI” suffix to their taglines, we feel we have evolved with the market to be the right database at the right time for the right movement. By the way, we weren't entirely exempt from this ourselves. Our old website told a version of that story too: database first, AI angle bolted on.
If agents are going to need to be more autonomous and “human-like” then they will need to think reason and act by themselves. They will need to coordinate with each other and they will need complete, up to the millisecond insight across important business context. They’ll need to do all of this in real-time and at scale.
Every other database or pipelined architecture will struggle to deliver on these requirements. This new autonomous agent paradigm requires a fresh look at the underlying data sources, and that is what RegattaDB is.
For many, including myself, this seems unattainable: serializable transactions and complex analytics at scale with acceptable performance. It isn’t, and we can prove it. The benchmarks are public , and we would love to explore this with you.
The RegattaDB service is also available and if you want to run it, you can start there.
This is why we reworked regatta.dev. We didn’t just append a better AI story to our existing narative, but we started with the data requirements for Agentic AI and let the use cases follow from that. This new site is a V1 and we'll keep building and adding to it. But if you want to see how we think this fits into the modernization work happening in organizations right now, that's the place to start.
We would like to hear what you think. If something is unclear, missing, or lands differently than we intended, that feedback is genuinely useful to us. And if you are ready to try it, getting started is straightforward from there.

RegattaDB Launches as the Database Built for AI Agents — Unifying OLTP, OLAP, and Vectors RegattaDB unifies transactions, analytics,...
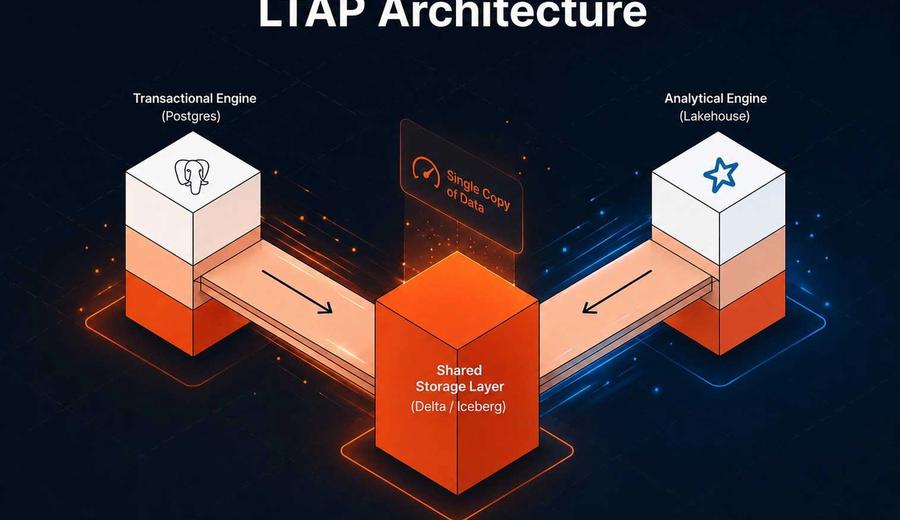
A few weeks ago we published an analysis of Databricks LTAP and the architectural questions it left open. One question in particular...

Databricks made a significant announcement at Data + AI Summit this week. LTAP, or Lake Transactional/Analytical Processing, is their answer to a problem the...