What workloads can you converge with RegattaDB?

Jim Walker
Chief Product Officer
Jim Walker
Chief Product Officer
Databases are architected for one thing. You pick Postgres for transactions, Snowflake for analytics, Pinecone for vector search, then write the pipelines to connect them. This data architecture has worked for years, but it is inefficient and will not suffice for our agentic AI future. Agents will need to think, reason and act, all at once and in real-time. We’ll need to converge these workloads.
The problem isn’t that any one of these tools are insufficient. Rather, they were built years ago and designed to optimize for a singular purpose:
When you need all three you’re required to have pipelines, replication lag, and consistency bugs across system boundaries. RegattaDB combines OLTP, OLAP, and vector search in a single engine with a shared concurrency model. No replication pipelines. No cross-system synchronization. One place to read live state, run analytical queries, and search by semantic similarity.
This unique, unified set of capabilities has been attempted but never accomplished, so identifying HOW to use converged workloads is a challenge for many. We just haven’t been able to dream of this in the past.
Below are some of the workloads where OLTP, OLAP, and vector need to operate together within a single transaction or agent loop. Separating them across systems isn’t just inconvenient, it breaks the use case entirely.
Every organization has its own version of these problems, shaped by its own data, scale, and operational constraints. The examples here are a starting point for thinking about the art of the possible or of what becomes possible when the boundaries between types of workloads disappear.
This is not an exhaustive map of where RegattaDB fits, rather it is inspirational. What converged workloads can you dream of?
When you deploy agents at scale, state management becomes a reliability problem. Agents run concurrently, modify shared records, and fail. Without a way to checkpoint and resume, you lose context and visibility into what went wrong.
RegattaDB gives you persistent, queryable agent state across an entire fleet. Every agent instance can checkpoint its current state, including memory context, task progress, and execution metadata. If an agent fails or is interrupted, it resumes from the last consistent checkpoint.
The OLTP layer handles checkpoint writes and coordination under high concurrency with serializable consistency. The OLAP layer lets you query historical state transitions to find failure patterns and performance bottlenecks without needing a separate observability pipeline. The vector layer lets you search across agent reasoning paths and decision traces to detect drift or find semantically similar past outcomes.
This is not a monitoring tool layered on top of your database. Agent state is stored as operational data, and queryable the same way as everything else.
Personalization systems often break down at the execution step. You can analyze what a customer is likely to want, but acting on that analysis in the same transaction requires crossing into a separate operational system.
With RegattaDB, the analysis and the execution share a data layer. The OLTP layer holds live customer profiles, inventory, pricing, and cart state. The OLAP layer evaluates purchasing behavior, cohort trends, and margin data to determine which offer to make. The vector layer finds products with similar attributes and purchase patterns to the customer’s history.
You can evaluate context, decide on an offer, and write the transaction to the customer record in a single pass. There is no handoff between systems and no lag between insight and action.
Support personnel (or agents) perform better when they have access to both the customer’s current state and the full history of how similar problems were resolved. That combination typically requires querying two or three separate systems.
RegattaDB gives support agents one place to check ticket status and entitlements (OLTP), analyze resolution patterns and escalation trends across historical data (OLAP), and run semantic search across past tickets, call transcripts, and knowledge base articles to find contextually relevant solutions (vector).
The agent can update a case, issue credit, or trigger a workflow from the same system it used to look up the answer.
NOC automation works best when you (or agents) can detect anomalies, compare them to prior incidents, and take corrective action without waiting on a human in the loop. That requires real-time signal ingestion, historical pattern analysis, and semantic similarity search, coordinated under transactional consistency.
The OLTP layer tracks device state across a huge number of devices, configuration changes, and incident records as they happen. The OLAP layer correlates failures, latency patterns, and configuration changes to surface systemic risk. The vector layer matches current anomaly signatures to historically similar incidents and their remediation steps. And with MCP, a resource could query incidents, in real-time, in the field and in their natural language.
The result is a system that can move from detection to action within a single operational loop, with a complete audit record of everything it did.
Threat detection depends on behavioral baselines, pattern recognition, and fast enforcement. When those capabilities live in separate systems, there is lag between detection and response.
RegattaDB maintains real-time security state in the OLTP layer, including sessions, authentication events, permission changes, and device posture. The OLAP layer establishes behavioral baselines and evaluates deviations across users and systems. The vector layer compares logs, alerts, and threat intelligence feeds to prior incident records to find attack patterns that rule-based systems would miss.
An agent operating across this layer can detect a threat, evaluate its severity relative to historical incidents, and take enforcement action in the same transaction.
Fraud detection requires evaluating a transaction in real time, comparing it to behavioral patterns over time, and matching it against known fraud signatures. These are three different query types against the same data.
The OLTP layer processes live transactions and enforces consistency at the moment of authorization. The OLAP layer evaluates velocity, geographic deviation, and behavioral aggregates to identify statistical anomalies. The vector layer compares the current transaction sequence to embeddings of known fraud cases to catch patterns that fall outside explicit rules.
All three happen without moving data between systems, which matters when the window for action is milliseconds.
RegattaDB may not be a replacement for the purpose-built execution infrastructure that high-frequency trading requires. It is a good fit, however for the risk management, compliance, and analytical layers that sit alongside it, and in those layers, the architectural problem is the same one that appears everywhere else in this post: the data you need to make a decision lives in more than one system, and moving it between them costs you time and consistency you cannot afford. Risk evaluation, position analytics, and pattern-based signal detection are typically handled by separate systems and by the time data has moved between them, the basis for a decision has already changed. RegattaDB keeps all three query types on the same data.
The OLTP layer maintains live position state, order books, and trade records with the consistency guarantees that financial systems require. The OLAP layer evaluates portfolio exposure, margin requirements, and risk aggregates in real time, without waiting for data to land in a separate analytics system. The vector layer compares current market conditions and order flow patterns to historical analogs to surface signals that rule-based models would not catch.
In an environment where the gap between what your data says and what your systems know about it has direct financial consequences, that architectural consolidation is not a convenience. It is a risk control.
Not every compelling use case requires all three layers working simultaneously. These workloads are primarily two-layer problems, but they illustrate a different kind of value: eliminating the operational cost of maintaining two separate specialized systems with a synchronization pipeline between them. The benefit is simpler architecture and fresher data, not three-way query coordination.
Traditional analytics stacks require you to replicate operational data into a warehouse before you can run analytical queries against it. For inventory, that means your analytics are always a pipeline delay behind reality. You might even know your stock levels as of thirty minutes ago, but not right now.
RegattaDB lets you run OLAP queries directly against live operational inventory data. The OLTP layer holds current stock levels, reservation state, and fulfillment records as transactions happen. The OLAP layer runs aggregations, trend analysis, and demand forecasting against that same data without waiting for a replication cycle.
The result is analytical queries that reflect the actual current state of your inventory, which matters when you are making pricing decisions, triggering reorders, or managing allocation across a large number of SKUs at scale.
Vector search is typically implemented against a pre-indexed snapshot of your data. That works well when the underlying data is relatively static, but breaks down when freshness matters. A semantic search over customer records, support tickets, or product listings that were indexed an hour ago may return results that no longer reflect reality.
RegattaDB lets you run semantic search against data that is current at index time. The OLTP layer ensures the records being searched reflect live state. The vector layer runs similarity queries against that data without requiring a separate indexing pipeline or accepting a freshness tradeoff.
This matters most in environments where data changes frequently and users expect search results to reflect the most current state of the world.
Every use case above demonstrates the cost of moving data between specialized systems. Sometimes that cost shows up as broken transactional consistency across three query types. Sometimes it is the quiet tax of pipelines, replication lag, and the organizational overhead of keeping multiple systems honest with each other. Either way, the legacy architecture is constraining what you can build before you have even started designing it.
Stitching together best-of-breed systems was a reasonable answer when workloads were predictable, and we functioned at human scale. With agents, this is no longer reasonable. The coordination overhead, the consistency gaps, and the latency are not engineering problems that can be oprtimized. They are structural limitations of the architecture itself.
The most compelling reason to explore RegattaDB is not any single use case. It is the question of what becomes possible when the constraint disappears entirely. When live state, historical patterns, and semantic similarity are always available together, in the same query, against the same data, the design space for what your systems can do changes. Problems that required workarounds become tractable. Use cases that were too complex to justify become straightforward.
The examples in this post are meant to open that door, not to define what is on the other side of it.

Databricks made a significant announcement at Data + AI Summit this week. LTAP, or Lake Transactional/Analytical Processing, is their answer to a problem the...
Things are moving fast. The market has shifted from "should we build agents" to "we are building and will...
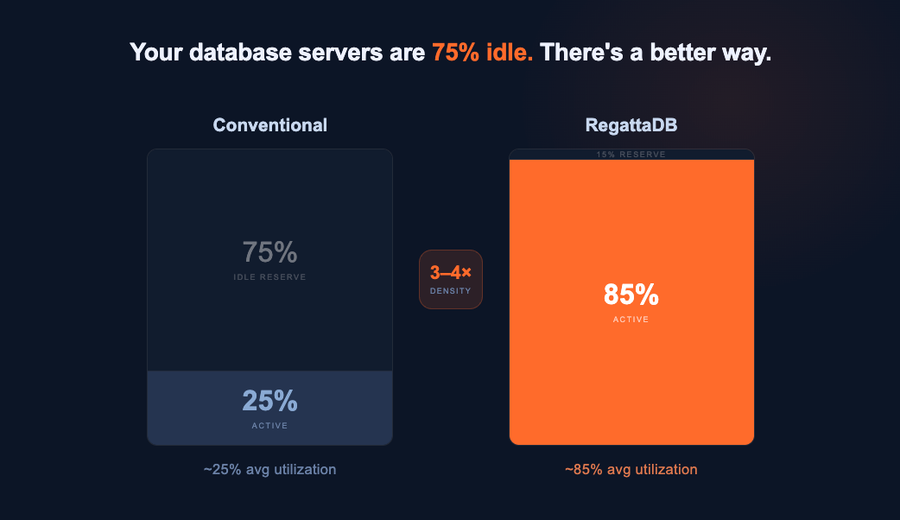
TL;DR - RegattaDB runs four applications on the hardware you'd normally use for one, without pipelines, without extra...