
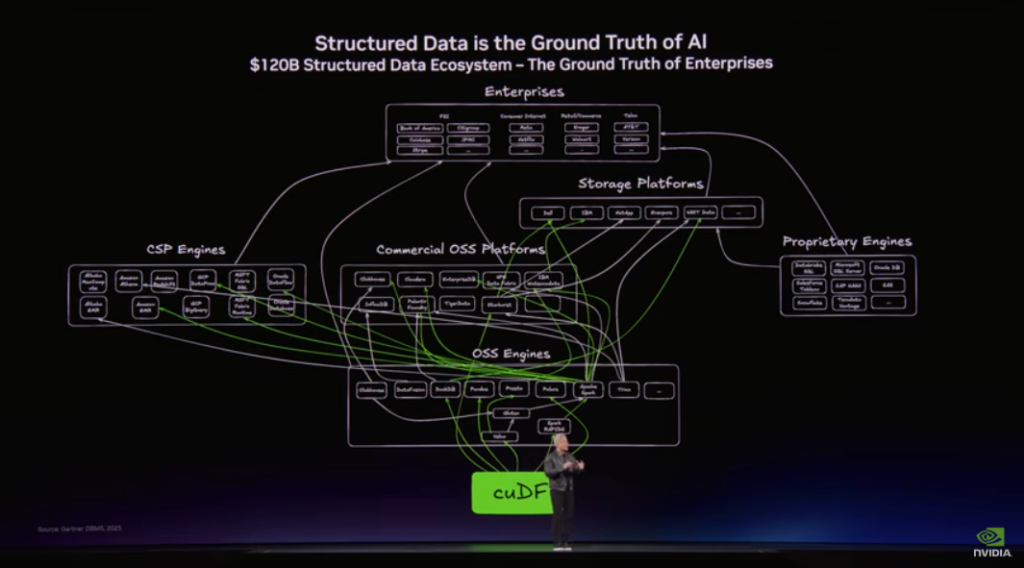
NVIDIA predicts a $120B expansion in data infrastructure to support Agentic AI. But for AI agents to reason and act,…
Read More >
SUMMARY: The Shift to Agentic AI is real: Moving beyond basic LLMs, the Agentic Era focuses on AI systems that can reason, coordinate, and execute complex real-world transactions.
- The Data Bottleneck: While GPUs provide the engine, the primary obstacle to AI autonomy is the database layer, which must provide a truth for agents to act upon.
- Transactional Integrity: To prevent “hallucinations” in execution (like double-selling inventory), AI agents require strict serializable isolation and real-time data consistency.
- RegattaDB Performance: TPC-C benchmark shows RegattaDB maintains linear scale and 98% efficiency even at extreme scales (1.5 million warehouses), and delivers the throughput needed for massive AI agent systems.
- Context Fabric for Agent Systems: RegattaDB acts as a shared memory layer, allowing AI agents to collaborate on the same data without state drift or conflicts.
In Monday’s GTC 2026 keynote, Jensen Huang highlighted that the next phase of the AI gold rush is agentic systems. He also called out that there needs to be a massive $120B expansion in spend on data infrastructure to make structured data usable for these new agent systems.
His argument is that while LLMs are the “engine,” structured data is the “ground truth.” For AI agents to actually perform work (like managing a portfolio, processing insurance claims or managing supply chains), they need a high-performance, real-time data layer that can handle massive transactional loads without collapsing and with high integrity.
We agree… RegattaDB plays directly into this pillar of NVIDIA’s ecosystem.
Why RegattaDB is the Ground Truth for NVIDIA’s Agentic Era
As NVIDIA moves from selling individual GPUs to selling entire AI Factory racks (like the Vera Rubin NVL72), the bottleneck shifts to how fast a database can record the actions of thousands of concurrent AI agents and then allow them to reason over this collective live operational data.
The value of RegattaDB maps directly to the specific mechanics of an NVIDIA-powered agentic ecosystem:
- The Agent Execution Engine: Think, Reason, Act
RegattaDB transforms AI from a chatbot into a thinking and transacting entity. It delivers serializable isolation at massive scale and allows agents to perform complex analysis and guaranteed state changes on the same operational data. When an agent reasons about an inventory adjustment and then acts, RegattaDB ensures Jensen’s “ground truth” remains current and immutable with transactional integrity.
- An Agent Context Fabric: Memory, Collaboration, and Coordination
As Jensen noted, AI “swarms” require a high-performance data layer to prevent state drift. RegattaDB acts as a linearizable memory layer, providing the shared state necessary for multiple agents to coordinate on complex projects without overwriting each other. It serves as the “common ground” for both short-term context and long-term history within the AI Factory.
- Agentic Scale: Efficient Performance
To justify the $120B CapEx of a Vera Rubin deployment, infrastructure must be hyper-efficient. RegattaDB delivers 12.6 tpmC (98% efficiency), eliminating the latencies and costs of moving data between silos. By unifying transactional, analytical, and vector reasoning in a single database, it provides the performance and efficiency density required as agentic data volumes explode.
The future is today, we have technical proof
The last point above is critical. We can build intelligent agent systems, but if they don’t scale with efficiency, they’ll never become a reality. And if we build on our legacy data architectures, these modern agent systems will only inherit their limitations. Over the past few months, we posted a few blog posts that speak to how we can scale both transactions and analytics at the same time.
First, we published an in depth demo of a complex 20B row analytical join at the same time as the database was executing 50,000 transactions per second. Second, we pushed a post that provides technical breakdown of a TPC-C benchmark that showed how RegattaDB can maintain 98% efficiency under the extreme concurrency Jensen described in his keynote.
The results provide a concrete proof point for how RegattaDB handles the data gravity problem Jensen described. As NVIDIA transitions from Blackwell to the Vera Rubin architecture, the focus shifts toward computational density. As agent systems scale, they will need to get more work done per rack with lower power overhead. And as the supporting structured data for these NVIDIA-powered stacks get built out, the RegattaDB ability to maintain high efficiency at extreme scale becomes a primary competitive advantage. His comments map directly to results we outlined in this benchmark.
What is the bottleneck in Agentic AI?
| Jensen’s “AI Factory” Requirement | Regatta Performance Metric |
| Agents Execution (think, reason and transact | 20B Row Join w/ 50K transactions |
| High Throughput (Feeding the GPU) | 750,000+ Transactions Per Second |
| Extreme Scale (Global Data Ecosystem) | 1.5 Million TPC-C Warehouses |
| Resource Efficiency (Lower TCO/Power) | 98% Efficiency on 50-node Cluster |
| Growth (Modular Expansion) | 12.6 tpmC per warehouse (Linear) |
Benchmark Insight 1: Massive Concurrency without “Thrashing”
While traditional databases hit a performance degradation under parallel requests, RegattaDB eliminated contention in a 1.5 million warehouse environment. Maintaining 98% efficiency across 50 nodes ensures CPU cycles are spent on processing rather than internal coordination. For Vera Rubin deployments, this translates to maximum ROI on NVLink interconnects by removing the database bottleneck and allowing for linear scale.
Benchmark Insight 2: Linear Scale for “AI Factories”
NVIDIA’s $120B modular vision requires a data layer that scales in lockstep with Grace Blackwell or Rubin units. RegattaDB demonstrated a consistent 12.6 tpmC per warehouse as the cluster grew, providing the linear predictability enterprise architects need. This guarantees that doubling hardware spend actually doubles transactional throughput for AI agents.
Benchmark Insight 3: Real-Time Consistency for Agentic Actions
Consider a supply chain agent managing 10,000 concurrent purchase orders across a global warehouse network. At step 3 of a 12-step fulfillment workflow, the agent reads inventory levels, but a legacy database serving stale data shows 500 units available when 480 have already been committed by parallel agents. By step 12, the agent has confidently confirmed shipments it cannot fulfill, triggering cascading failures across downstream logistics, finance reconciliation, and customer SLAs. This isn’t a hypothetical. It’s the default behavior of any database that can’t guarantee serializable isolation under high concurrency. Without a ground truth that is both real-time and consistent, AI agents don’t just make mistakes, they manufacture confidence in those mistakes.
To prevent agents from using stale or incorrect data, like the example above, strict serializable isolation is non-negotiable. Achieving 750,000+ TPS under strict serializable isolation proves RegattaDB can serve as the system of record for NVIDIA’s vision. It ensures every agentic decision is recorded instantly and accurately across the global fabric. Further, execution of a massive, complex analytical join at the same time as you commit 50k transactions per second demonstrates that RegattaDB can both act and think at the same time, on the same live operational data.
The future of Agentic systems is live context
The move toward autonomous AI agent systems requires a fundamental rethink of the data layer that these systems are built on. Simple adoption of legacy infrastructure will not suffice as agents will need reasoning and real-time execution in real-time. They need a reliable, operational truth of the current state of the business delivered through strict serializable isolation, ad-hoc large scale analytics and linear scale. RegattaDB addresses this gap and helps turn the NVIDIA “AI Factories” into actionable execution engines.
Ready to benchmark RegattaDB against your agent workload?
Start here -> info@regatta.dev

